[삼성 SDS Brightics] 개인 분석 과제 - 3. 군집 분석 (1) K-means 군집분석 / Brightics로 군집 분석 해 보기!

안녕하세요, 은서예요 !_!
이번 주는 드디어 군집 분석에 들어갑니닷
하지만 저는 군집 분석을 해 보는 것이 처음이기도 하고, 제대로 공부해 본 적이 없어서
이번 기회를 통해 군집 분석을 자세히 공부해 보도록 하겠습니다 !
오늘은 proDS 시험을 보고 왔는데,, 눈물이 도르륵 나네요,, ㅜ
제발 결과가 잘 나오기를

피드백 받은 사항 수정하기
저번 포스팅을 보시고 멘토님께서 정말 감사하게도 피드백을 남겨 주셨습니다 ㅎ.ㅎ
그래서 피드백 받은 부분을 먼저 수정하겠습니다
멘토님께서 말씀해 주신 부분은 두 가지였습니다!
첫 번째, <Income 변수에 로그 취하기>
멘토님께서 조언해 주시기를, 보통 수입 변수에는 로그값을 취한다고 합니다
그래서 이유가 무엇인지, 제 데이터셋에도 로그 변환을 해 줄 필요가 있는지 알아봤어요
보통 Income 변수에 로그 변환을 해 주는 이유는 데이터 편차를 줄이기 위함입니다
소득, 재산과 같은 변수는 매우 편차가 큰 데이터에 속하죠!
오른쪽으로 꼬리가 긴 분포를 가지며 정규분포를 갖기 어렵기 때문에 로그함수를 취함으로써 원활한 해석에 도움을 줄 수 있습니다
그렇다면 제 데이터셋의 Income 변수는 어떤 분포를 가지고 있는지 확인해 보겠습니다 !_!

Income 변수의 히스토그램을 보았더니 생각보다 왼쪽으로 치우쳐져 있지 않았어요!
제가 전처리 단계에서 이상치를 제거해 준 것도 도움이 되지 않았나 싶기도 합니다 ㅎ ㅎ
혹시 몰라서 log를 취한 뒤 비교해 봤더니

로그 변환을 했을 때에는 이렇게 오른쪽으로 치우쳐져 나타나더라구요
로그 변환은 패스해도 되겠다는 결론을 얻었습니다~!
두 번째, <막대그래프 Y축 sum에서 average(평균 소비량)으로 바꿔 보기>
두 번째는 제가 이전 포스팅에서 시각화를 했을 때
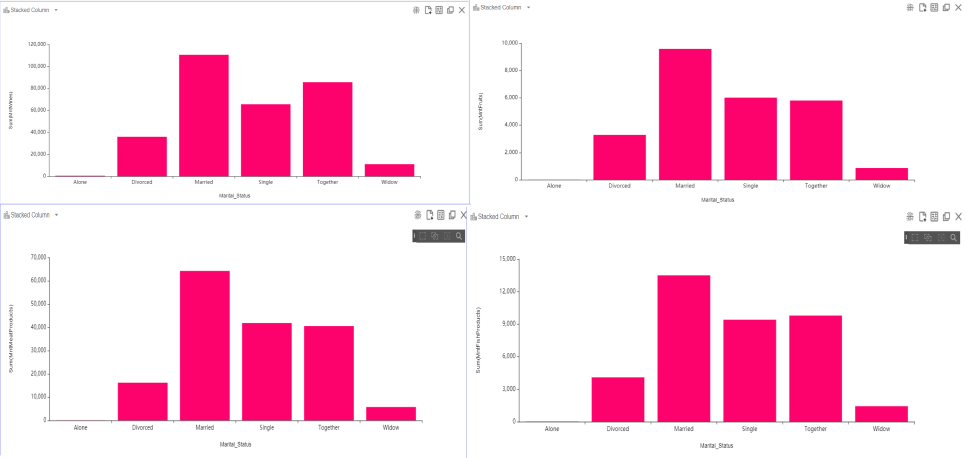
이렇게 막대 그래프를 그렸었는데요!
세로축이 Sum으로 설정되어 있어서 혹시 Married 변수의 데이터량 자체가 많아
총합이 항상 크게 나오는 게 아닐까 하는 멘토님의 말씀을 받았습니다
그래서 세로축을 Sum이 아닌 average로 놓고 다시 돌려 보기로 했어용
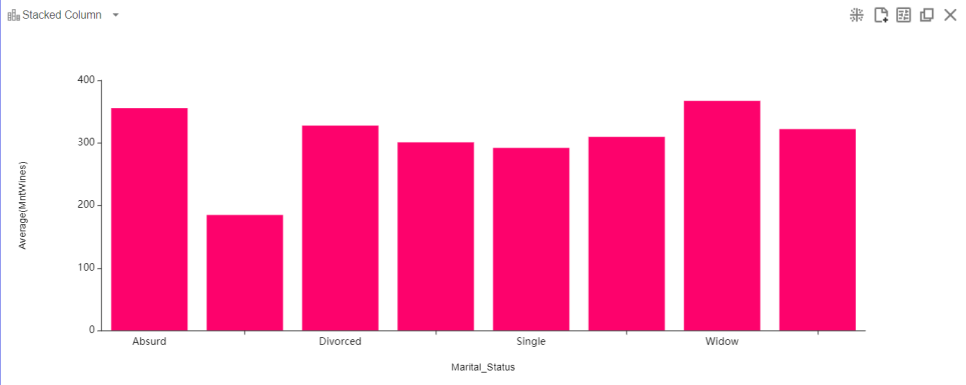
그랬더니 결과가 이렇게 나왔습니다 ! ! ! (컬럼명이 몇 개가 안 보이는데 커서를 올리면 상세한 수치와 함께 뜹니다)
전과 다르게 차이가 줄어들었네요?? 유의미한 차이가 있는지는 차차 살펴보도록 하겠습니다 ㅎ ㅎ
멘토님 감사드려요~!

군집 분석이란?
자, 이제 드디어 <군집 분석>을 본격적으로 시작해 보겠슴닷
시작하기 전에 개념 정리부터 해야겠죠?!
군집 분석 (Cluster analysis)
간의 유사도를 정의하고 그 유사도에 가까운 것부터 순서대로 합쳐 가는 방법으로, 유사도의 정의에는 거리나 상관계수 등 여러 가지가 있다. 군집 분석에는 차례대로 합쳐 가는 계층적 방법 이외에, 요인 분석 등으로 미리 군집을 예상하여 합쳐 가는 비계층적 방법도 있다.
[네이버 지식백과] 군집 분석 [cluster analysis] (실험심리학용어사전, 2008., 곽호완, 박창호, 이태연, 김문수, 진영선)
쉽게 말해서 유사한 정도에 따라 그룹을 나눈다!고 할 수 있는 데이터 분석 기법입니다
그리고 군집 분석 기법 중 저는 K-means 군집 분석을 사용해 보려고 해요 ㅎㅎ
k-means clustering
각 군집에 할당된 포인트의 평균 좌표를 보고
군집의 중심점을 점점 업데이트 하여 군집을 나누는 모델
예를 들어서 A, B 군집 포인트가 있다면 이 포인트와 데이터 간의 거리를 측정하여 더 가까운 포인트로 할당되는 것이죠!
단! k-means 군집 분석에는 초모수 K가 있습니다
K는 미리 군집의 개수를 정해서 설정해 놓을 수도 있지만, Elbow method와 silhouete method 2가지 방법을 통해서도 알 수 있답니당
(k-means clustering은 아래 블로그 링크를 참고해서 공부했습니다! 첨부해 드릴게욧 잘 정리되어 있더라고요)
https://blog.naver.com/jaehong7719/221937656718
그리고 저는 Brightics를 통해 Silhoutte method를 사용해 볼 계획이에요
Silhoutte method란 ?
객체와 그 객체가 속한 군집의 데이터들과의 거리를 계산하는 방법으로, silhoutte 값이 1에 가까울수록 분류가 잘 되었다고 판단할 수 있습니다
오늘 포스팅에서는 Brightics에서 K-means 함수를 일단 간단하게 사용해 보려고 해요 !_! (맛보기 늑김)

먼저 split data 함수로 데이터를 나누어 줬습니다

그리고 ㄷ두두등장한 K-means 함수! 저는 silhoutte method를 활용할 것이기 때문에
그냥 K-means 함수가 아닌 silhoutte이 붙어 있는!! 함수를 사용했슴니다
초모수 K를 3, 4, 5로 넣어 주고 Input columns에는 소비자의 신상과 구매량 변수만 일단 넣어 볼게용
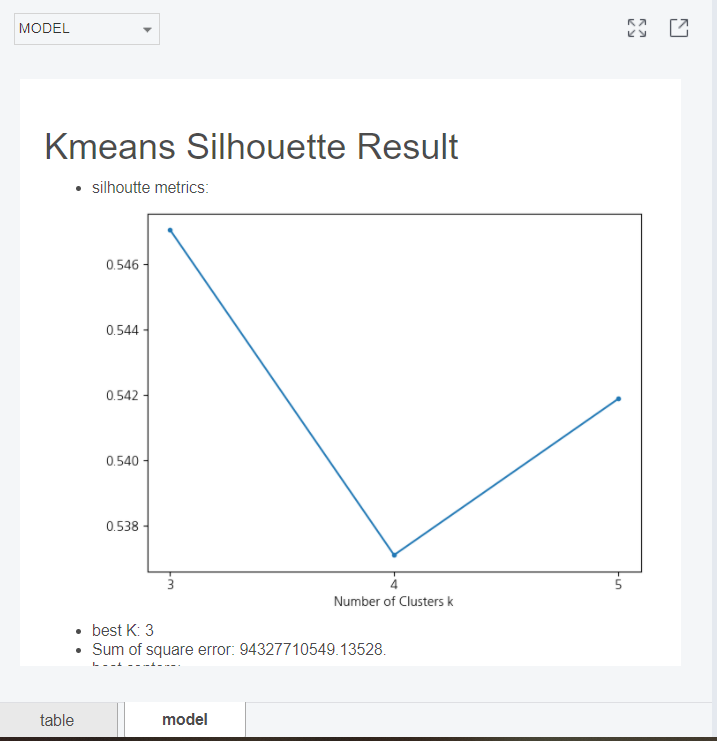
여기서 꿀팁 ! ! !
처음 모델을 돌리면 모델 화면이 아니라 데이터 테이블만 나올 텐데
하단의 model 창을 꼭 클릭해 주셔야 합니닷
저는 못 보고 지나쳐서 조금,, 헤맸어요 ㅜ.ㅜ
모델을 확인해 보니 best K가 3이라고 나오네요!

그런데 밑을 내려서 그래프를 살펴보니 유의미하게 클러스터를 나눌 수 있는 변수가 Income뿐이더라고요...
silhoutte 계수도 높지 않아서 ㅜ ㅜ 일단 이번 시도는 함수를 다뤄 본 것 + 군집분석 공부로 만족하고
다음 포스팅에서 유의미한 결과를 낼 수 있는 방법을 공개해 보도록 하겠습니닷
여러분도 기대되시죠 ?!
끝까지 지켜봐 주세요 ㅎ.ㅎ
그럼 안농~!

본 포스팅은 삼성 SDS Brightics 서포터즈 활동의 일환으로 작성되었습니다.
#삼성SDS #Brightics #BrighticsA#브라이틱스 #데이터분석 #데이터사이언스 #인공지능 #브라이틱스서포터즈 #EDA #데이터전처리 #서포터즈#대외활동#분석프로그램 #Xgboost #Regression #선형회귀 #Kaggle #KaggleCompetition #HousePrice #데이터시각화 #R#Rstudio#Python#SamsungSDS#삼성서포터즈#코딩#통계#iris#삼성#분석플랫폼#모델링#머신러닝#데이터분석툴#빅데이터#브라이틱스서포터즈2기#서포터즈2기#삼성SDSBrightics #BrighticsStudio #브라이틱스 #모델링 #데이터분석 #데이터 #브라이틱스서포터즈 #Brightics서포터즈 #브라이틱스다운 #모델링 #데이터시각화 #프로그램설치
#Brightics설치방법 #파이썬 #python #R #Rstudio #코딩 #코딩없이분석 #삼성SDS #삼성서포터즈 #데이터분석대외활동 #대외활동 #코딩하는법